Install, Run & ControlEverythingon Your Computerwith 1 Click.
Pinokio is a browser that lets you install, run, and programmatically control ANY application, automatically.
Explore
Browse the Pinokio scripts shared by the community.
Verified
Scripts from Verified Publishers
script version 2.0
ditto
the simplest self-building coding agent https://github.com/yoheinakajima/ditto

script version 2.0
e2-f5-tts
F5-TTS: A Fairytaler that Fakes Fluent and Faithful Speech with Flow Matching https://huggingface.co/spaces/mrfakename/E2-F5-TTS
script version 2.0
diamond
Diffusion for World Modeling https://diamond-wm.github.io/

script version 2.0
Open WebUI
User-friendly WebUI for LLMs, supported LLM runners include Ollama and OpenAI-compatible APIs https://github.com/open-webui/open-webui

script version 2.0
facepoke
[NVIDIA Only] Select a portrait, click to move the head around https://github.com/jbilcke-hf/FacePoke

script version 2.0
MLX-Video-Transcription
[Mac Only] Super Fast MLX Powered Video Transcription https://github.com/RayFernando1337/MLX-Auto-Subtitled-Video-Generator/ by https://x.com/RayFernando1337

script version 1.5
Invoke
The Gen AI Platform for Pro Studios https://github.com/invoke-ai/InvokeAI

script version 2.0
diffusers-image-fill
Remove objects from an image https://huggingface.co/spaces/OzzyGT/diffusers-image-fill

script version 1.5
FaceFusion 3.0.0
Industry leading face manipulation platform

script version 2.0
Whisper-WebUI
A Web UI for easy subtitle using whisper model.

script version 2.1
CogStudio
[NVIDIA ONLY] Advanced Web UI for CogVideo (text to video, image to video, video to video, extend video, etc) -- Generate videos with less than 10GB VRAM

script version 2.0
moshi
[Mac only] a speech-text foundation model for real time dialogue https://github.com/kyutai-labs/moshi

script version 2.1.0
Applio
A simple, high-quality voice conversion tool focused on ease of use and performance. https://github.com/IAHispano/Applio

script version 2.1
fluxgym
[NVIDIA Only] Dead simple web UI for training FLUX LoRA with LOW VRAM support (From 12GB)

script version 2.0
Comfyui
The most powerful and modular diffusion model GUI, api and backend with a graph/nodes interface. https://github.com/comfyanonymous/ComfyUI

script version 2.0
Forge
[NVIDIA ONLY] The most efficient way to run FLUX (Optimized to run even on low memory machines, as low as 3GB VRAM with 512x512 resolution) https://github.com/lllyasviel/stable-diffusion-webui-forge

script version 2.0
LivePortrait
Bring portraits to life! https://github.com/KwaiVGI/LivePortrait

script version 2.0
flux-webui
Minimal Flux Web UI powered by Gradio & Diffusers (Flux Schnell + Flux Merged)

script version 2.0
aura-sr-upscaler
AuraSR-v2 - An open reproduction of the GigaGAN Upscaler from fal.ai https://huggingface.co/spaces/gokaygokay/AuraSR-v2

script version 2.0
audiocraft_plus
AudioCraft Plus is an all-in-one WebUI for the original AudioCraft, adding many quality features on top https://github.com/GrandaddyShmax/audiocraft_plus

script version 2.0
artist
Artist is a training-free text-driven image stylization method. You give an image and input a prompt describing the desired style, Artist give you the stylized image in that style. The detail of the original image and the style you provide is harmonically integrated https://huggingface.co/spaces/fffiloni/Artist

script version 2.0
RC Stable Audio Tools
Advanced Gradio UI for Stable Audio https://github.com/RoyalCities/RC-stable-audio-tools

script version 2.0
PhotoMaker2
Customizing Realistic Human Photos via Stacked ID Embedding https://huggingface.co/spaces/TencentARC/PhotoMaker-V2

script version 2.0
Fooocus
Minimal Stable Diffusion UI

script version 2.0
autogpt
AutoGPT is a powerful tool that lets you create and run intelligent agents https://github.com/Significant-Gravitas/AutoGPT

script version 2.0
gepeto
Generate Pinokio Launchers, Instantly. https://gepeto.pinokio.computer

script version 1.5
Florence2
An advanced vision foundation model from MicroSoft https://huggingface.co/spaces/gokaygokay/Florence-2

script version 1.5
hallo
[NVIDIA Only] Hierarchical Audio-Driven Visual Synthesis for Portrait Image Animation https://github.com/fudan-generative-vision/hallo

script version 1.5
chat-with-mlx
[Mac Onlyl] An all-in-one LLMs Chat UI for Apple Silicon Mac using MLX Framework. https://github.com/qnguyen3/chat-with-mlx

script version 1.5
flashdiffusion
Accelerating any conditional diffusion model for few steps image generation https://gojasper.github.io/flash-diffusion-project/

script version 1.5
StableAudio
An Open Source Model for Audio Samples and Sound Design https://github.com/Stability-AI/stable-audio-tools

script version 1.5
PCM
Phased Consistency Model - generate high quality images with 2 steps https://huggingface.co/spaces/radames/Phased-Consistency-Model-PCM

script version 1.5
SillyTavern
a local-install interface that allows you to interact with text generation AIs (LLMs) to chat and roleplay with custom characters. https://docs.sillytavern.app/

script version 1.5
AITown
Build and customize your own version of AI town - a virtual town where AI characters live, chat and socialize https://github.com/a16z-infra/ai-town

script version 1.5
LlamaFactory
Unify Efficient Fine-Tuning of 100+ LLMs https://github.com/hiyouga/LLaMA-Factory

script version 1.5
openui
Describe UI and see it rendered live. Ask for changes and convert HTML to React, Svelte, Web Components, etc. Like vercel v0, but open source https://github.com/wandb/openui

script version 1.5
StoryDiffusion Comics
create a story by generating consistent images https://github.com/HVision-NKU/StoryDiffusion

script version 1.5
ZeST
ZeST: Zero-Shot Material Transfer from a Single Image. Local port of https://huggingface.co/spaces/fffiloni/ZeST (Project: https://ttchengab.github.io/zest/)

script version 1.5
Openvoice2
Openvoice 2 Web UI - A local web UI for Openvoice2, a multilingual voice cloning TTS https://x.com/myshell_ai/status/1783161876052066793
script version 1.2
Lobe Chat
An open-source, modern-design ChatGPT/LLMs UI/Framework. Supports speech-synthesis, multi-modal, and extensible (function call) plugin system. https://github.com/lobehub/lobe-chat

script version 1.5
IDM-VTON
Improving Diffusion Models for Authentic Virtual Try-on in the Wild https://huggingface.co/spaces/yisol/IDM-VTON

script version 1.5
devika
Agentic AI Software Engineer https://github.com/stitionai/devika

script version 1.5
CosXL
Edit images with just prompt, an unofficial demo for CosXL and CosXL Edit from Stability AI, https://huggingface.co/spaces/multimodalart/cosxl

script version 1.5
parler-tts
a lightweight text-to-speech (TTS) model that can generate high-quality speech with features that can be controlled using a simple text prompt (e.g. gender, background noise, speaking rate, pitch and reverberation). https://huggingface.co/spaces/parler-tts/parler_tts_mini

script version 1.5
instantstyle
Upload the picture of an image, and generate images with that image style. Instant generation with no LoRA required https://huggingface.co/spaces/InstantX/InstantStyle

script version 1.5
face-to-all
diffusers InstantID + ControlNet inspired by face-to-many from fofr (https://x.com/fofrAI) - a localized Version of https://huggingface.co/spaces/multimodalart/face-to-all

script version 1.5
CustomNet
A unified encoder-based framework for object customization in text-to-image diffusion models https://huggingface.co/spaces/TencentARC/CustomNet

script version 1.5
spright
Generate images with spatial accuracy https://huggingface.co/spaces/SPRIGHT-T2I/SPRIGHT-T2I

script version 1.5
brushnet
A Plug-and-Play Image Inpainting Model with Decomposed Dual-Branch Diffusion https://huggingface.co/spaces/TencentARC/BrushNet
script version 1.5
Arc2Face
A Foundation Model of Human Faces https://huggingface.co/spaces/FoivosPar/Arc2Face

script version 1.2
supir
[NVIDIA ONLY] Text-driven, intelligent restoration, blending AI technology with creativity to give every image a brand new life https://supir.xpixel.group

script version 1.2
moondream2
a tiny vision language model that kicks ass and runs anywhere https://github.com/vikhyat/moondream

script version 1.2
TripoSR
a state-of-the-art open-source model for fast feedforward 3D reconstruction from a single image, developed in collaboration between Tripo AI and Stability AI. https://huggingface.co/spaces/stabilityai/TripoSR

script version 1.2
ZETA
Zero-Shot Text-Based Audio Editing Using DDPM Inversion https://huggingface.co/spaces/hilamanor/audioEditing

script version 1.2
differential-diffusion-ui
Differential Diffusion modifies an image according to a text prompt, and according to a map that specifies the amount of change in each region https://differential-diffusion.github.io/

script version 1.3
dust3r
Geometric 3D Vision Made Easy https://dust3r.europe.naverlabs.com/

script version 1.2
Chatbot-Ollama
open source chat UI for Ollama https://github.com/ivanfioravanti/chatbot-ollama

script version 1.2
remove-video-bg
Video background removal tool https://huggingface.co/spaces/amirgame197/Remove-Video-Background

script version 1.2
MeloTTS
High-quality multi-lingual text-to-speech library by MyShell.ai. Support English, Spanish, French, Chinese, Japanese and Korean https://github.com/myshell-ai/MeloTTS
script version 1.2
gligen
An intuitive GUI for GLIGEN that uses ComfyUI in the backend https://github.com/mut-ex/gligen-gui

script version 1.3
Stable Cascade
Stable Cascade from StabilityAI

script version 1.1
Bark Voice Cloning
Upload a clean 20 seconds WAV file of the vocal persona you want to mimic, type your text-to-speech prompt and hit submit! A local version of https://huggingface.co/spaces/fffiloni/instant-TTS-Bark-cloning

script version 1.1
[NVIDIA GPU ONLY] LGM
LGM: Large Multi-View Gaussian Model for High-Resolution 3D Content Creation https://huggingface.co/spaces/ashawkey/LGM

script version 1.1
BRIA RMBG
Background removal model developed by BRIA.AI, trained on a carefully selected dataset and is available as an open-source model for non-commercial use https://huggingface.co/spaces/briaai/BRIA-RMBG-1.4

script version 1
VideoCrafter 2
[Runs fast on NVIDIA GPUs. Works on M1/M2/M3 Macs but slow] VideoCrafter is an open-source video generation and editing toolbox for crafting video content. It currently includes the Text2Video and Image2Video models https://github.com/AILab-CVC/VideoCrafter

script version 1.1
Moondream1
moondream1 is a tiny (1.6B parameter) vision language model trained by @vikhyatk that performs on par with models twice its size. It is trained on the LLaVa training dataset, and initialized with SigLIP as the vision tower and Phi-1.5 as the text encoder. https://huggingface.co/spaces/vikhyatk/moondream1

script version 1
InstantID
state-of-the-art tuning-free method to achieve ID-Preserving generation with only single image, supporting various downstream tasks. https://instantid.github.io/

script version 1
PhotoMaker
Customizing Realistic Human Photos via Stacked ID Embedding https://github.com/TencentARC/PhotoMaker

script version 1
MAGNeT
MAGNeT is a text-to-music and text-to-sound model capable of generating high-quality audio samples conditioned on text descriptions https://github.com/facebookresearch/audiocraft/blob/main/docs/MAGNET.md

script version 1
vid2pose
Video to Openpose & DWPose (All OS supported) https://github.com/sdbds/vid2pose
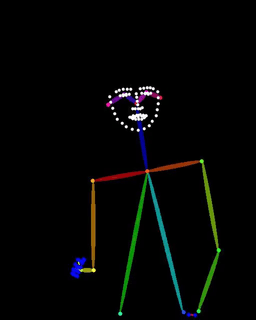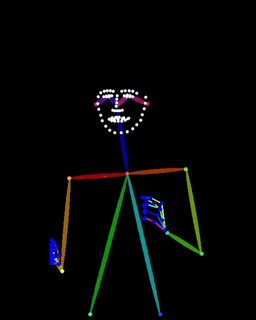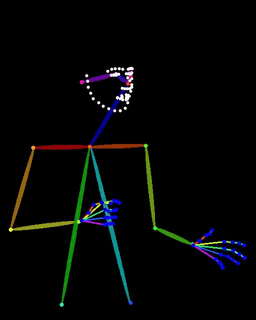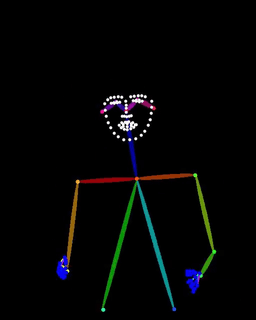
script version 1
Moore-AnimateAnyone-Mini
[NVIDIA ONLY] Efficient Implementation of Animate Anyone (13G VRAM + 2G model size) https://github.com/sdbds/Moore-AnimateAnyone-for-windows

script version 1
Moore-AnimateAnyone
[NVIDIA GPU ONLY] Unofficial Implementation of Animate Anyone https://github.com/MooreThreads/Moore-AnimateAnyone

script version 1
OpenVoice
Instantly clone any voice from any text to any speech, in any language https://huggingface.co/spaces/myshell-ai/OpenVoice

script version 1
IP-Adapter-FaceID
Enter a face image and transform it to any other image. Demo for the h94/IP-Adapter-FaceID model https://huggingface.co/spaces/multimodalart/Ip-Adapter-FaceID

script version 1
StreamDiffusion
[NVIDIA ONLY] A Pipeline-Level Solution for Real-Time Interactive Generation https://github.com/cumulo-autumn/StreamDiffusion

script version 1
dreamtalk
When Expressive Talking Head Generation Meets Diffusion Probabilistic Models (https://github.com/ali-vilab/dreamtalk)

script version 1.1
Stable Diffusion web UI
One-click launcher for Stable Diffusion web UI (AUTOMATIC1111/stable-diffusion-webui)

script version 1
Video2Openpose
Turn any video into Openpose video https://huggingface.co/spaces/fffiloni/video2openpose2
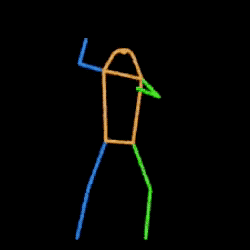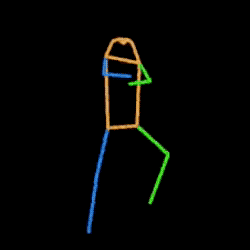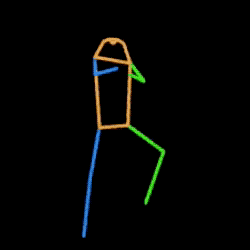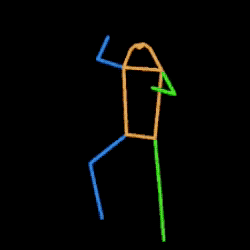
StyleAligned
Style Aligned Image Generation via Shared Attention https://style-aligned-gen.github.io/

Video2Openpose
Turn any video into Openpose video https://huggingface.co/spaces/fffiloni/video2openpose2
MagicAnimate Mini
[NVIDIA GPU Only] An optimized version of MagicAnimate https://github.com/sdbds/magic-animate-for-windows

Vid2DensePose
Convert your videos to densepose and use it on MagicAnimate https://github.com/Flode-Labs/vid2densepose

MagicAnimate
[NVIDIA GPU Only] Temporally Consistent Human Image Animation using Diffusion Model https://showlab.github.io/magicanimate/

Realtime StableDiffusion
Demo showcasing ~real-time Latent Consistency Model pipeline with Diffusers and a MJPEG stream server (https://github.com/radames/Real-Time-Latent-Consistency-Model)

lavie
Text-to-Video (T2V) generation framework from Vchitect https://github.com/Vchitect/LaVie

LEDITS++
Limitless Image Editing using Text-to-Image Models

Diffusers SDXL Turbo
Demo showcasing ~real-time Latent Consistency Model pipeline with Diffusers and a MJPEG stream server (https://github.com/radames/Real-Time-Latent-Consistency-Model)

sdxl turbo
A Real-Time Text-to-Image Generation Model

Stable Video Diffusion
[NVIDIA ONLY] Stable Video Diffusion Streamlit App. Currently supports Nvidia GPU machines only.

DEUS
A Realtime Creation Engine

Mirror
An AI powered mirror

Realtime BakLLaVA
llama.cpp with BakLLaVA model describes what does it see (https://github.com/Fuzzy-Search/realtime-bakllava)

LP-MusicCaps
LLM-Based Pseudo Music Captioning

AudioSep
Separate Anything You Describe (https://huggingface.co/spaces/Audio-AGI/AudioSep)

LCM
Fast Image generator using Latent consistency models https://replicate.com/blog/run-latent-consistency-model-on-mac

Text Generation WebUI
A Gradio web UI for Large Language Models https://github.com/oobabooga/text-generation-webui

IllusionDiffusion
Generate stunning illusion artwork with StableDiffusion (A space by @angrypenguinPNGAP - created with Monster Labs QR ControlNet.

XTTS
clone voices into different languages by using just a quick 3-second audio clip. (a local version of https://huggingface.co/spaces/coqui/xtts)

RVC
1 Click Installer for Retrieval-based-Voice-Conversion-WebUI (https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI)

kohya_ss
1 Click Installer for kohya_ss, a Stable Diffusion LoRa & Dreambooth WebUI (https://github.com/bmaltais/kohya_ss)

Tokenflow
Temporally consistent video editing. A local version of https://huggingface.co/spaces/weizmannscience/tokenflow

ModelScope Image2Video (Nvidia GPU only)
Turn any image into a video! (Web UI created by fffiloni: https://huggingface.co/spaces/fffiloni/MS-Image2Video)

VALL-E-X
An open source implementation of Microsoft's VALL-E X zero-shot TTS model

DenseDiffusion
Dense Text-to-Image Generation with Attention Modulation

LoRA the Explorer
Stable Diffusion LoRA Playground (HuggingFace: https://huggingface.co/spaces/multimodalart/LoraTheExplorer)

1 Click Control-Lora for ComfyUI
Install Control-Lora Models and Workflows to ComfyUI with 1 click

LDM 3D
[NVIDIA GPU ONLY] One click installer for Intel's ldm3d

Audio Webui
A webui for different audio related Neural Networks

AudioLDM 2
[Nvidia GPU only] One click installer for AudioLDM 2 Gradio UI
AudioGradio
One click installer for AudioCraft MusicGen and AudioGen Gradio UI (Requires at least Pinokio v0.0.56)

AnimateDiff
Install AnimateDiff Automatic1111 Extension and the models with one click

Xorbits Inference
LLM Web UI and API

llamacpp
Port of Facebook's LLaMA model in C/C++

Pinokio Tutorial
Simple script examples that highlight all the Pinokio APIs

Latest
Latest Pinokio scripts from the community (tagged as 'pinokio' on GitHub)